* 이 게시물 POSTECH 전지혁 교수 K-mooc 강의, 시계열 분석 기법 및 응용을 기반으로 합니다.
ARCH 모델
이 챕터에서는 자기회귀 조건부 이분산성(ARCH) 모델.극복하다
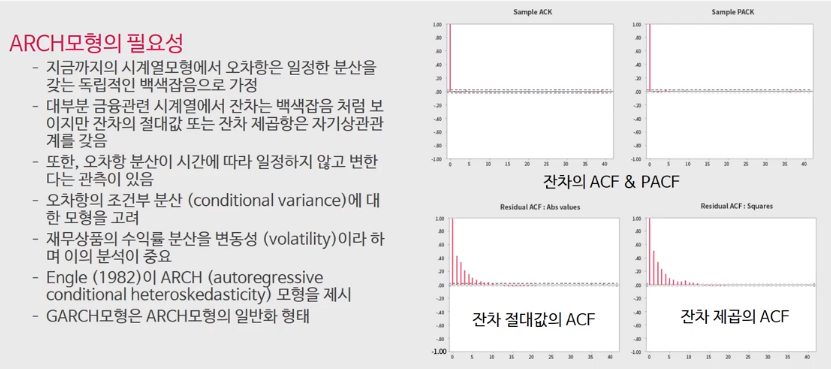
1주차부터 4주차까지는 오차항 $a_t$가 백색소음이라고 가정하여 시계열 모델을 구축하였지만, 실제로는 잔차가 완전히 설명되지 않는 경우가 많습니다. 재무 데이터의 경우 잔차의 ACF&PACF는 0으로 나타나지만 잔차를 절대값이나 제곱으로 다시 그리면 위 그림과 같이 자기상관이 있는 경우가 많다고 합니다. 또한 연구 결과에 따르면 잔차의 분산이 일정하지 않고 시간에 따라 변화한다는 관측이 있다.
따라서 이러한 ‘변동성’을 ARCH모형(Autoregressive Conditional *Heteroscedasticity)으로 분석하기 때문에 특히 금융상품의 경우 오차항의 조건부 분산도 고려해야 한다는 논의가 있어 왔다. 나타납니다.
*여기서 이분산성은 분산이 같지 않다는 것을 의미합니다(이분산성).
ARCH 모델의 표현

ARCH 모델이 표현되는 방식을 살펴보면 앞서 SARIMA에서 논의한 접근법과 유사하게 오차항이 특정한 관계를 갖는다는 가정이 추가된다. 차이점은 관계가 최소 제곱 항으로 표현되고 AR 모델을 따른다는 가정이 변경되었다는 것입니다.
$$u_t^2 = \alpha_0 + \alpha_1u_{t-1}^2 + \dots + \alpha_qu_{tq}^2 + w_t (w_t : 백색 잡음)$$
여기서 오차항의 조건부 분산을 찾으면,
$Var(u_t|u_{t-1},…) = E(u_t^2|u_{t-1},…)-E(u_t|u_{t-1},…) ^2$는 오류 항의 평균, 즉 $E(u_t|u_{t-1},…) = 0$, $Var(u_t|u_{t-1},…) = E이기 때문입니다. ( u_t ^2|u_{t-1},…)$이고 $E(w_t) = 0$이므로 최종 식의 형태는 다음과 같다.
$$\sigma_t^2 = Var(u_t|u_{t-1},…) = E(u_t^2|u_{t-1},…) = \alpha_0 + \alpha_1u_{t-1 }^2 + \dots + \alpha_qu_{t-1}^2$$
이 형태학적 모델을 ARCH(q) 모델이라고 합니다.
ARCH 모델의 정상성 조건
ARCH 모델에는 정상성 제약 조건도 필요합니다.
정의에 따르면 오차항의 분산(무조건 분산)은 시간 $\sigma_u^2$에 대해 일정하지만, 오차항의 조건부 분산 $\sigma_t^2$는 랜덤 노이즈를 제거하면 일정합니다. AR 모델을 따르고 시간이 지남에 따라 변경됩니다.

조건부 분산 $\sigma_t^2$에 대한 기대값을 취하면 무조건부 분산과 같아집니다. (자세한 파생 과정은 다루지 않습니다.)
$$\sigma_u^2 = \frac{\alpha_0}{1-\alpha_1-\dots-\alpha_q}$$
여기서 분산은 0보다 커야 하므로 정상성 조건은 $\alpha_1 + \dots + \alpha_q < 1$가 됩니다.
평균 방정식 및 분산 방정식

ARCH 모델은 원래 시계열이 있는 형태이고 추가적으로 오차항을 처리하는 모델이 있습니다. 이것을 분산 방정식이라고 합니다. 강의에서 개념은 다음과 같이 요약됩니다.
- 시계열 자체의 모델: 평균 방정식
- 오류 용어의 모델: 분산 방정식
따라서 ARCH를 포함하는 시계열 모델은 (시계열 모델명) – ARCH(n) 모델의 형태로 작성하고, 오차항을 포함하는 평균방정식과 오차항에 대한 분산방정식을 동시에 정의해야 한다. 위 그림과 같이 시계열이 일종의 AR이나 MA가 아닌 경우에도 사용할 수 있습니다.
ARCH-M 모델

ARCH-M도 일반적으로 사용되며 평균 방정식에 조건부 분산을 포함하는 모델을 의미합니다. (말그대로 평균방정식의 ARCH) 위의 다른 예와 달리 평균방정식에는 $u_t$뿐만 아니라 조건부 하위분포함수 $\sigma_t^2$도 정의되어 사용되는 것을 볼 수 있다.
즉 Y를 설명하는데 조건부 분산도 관여한다고 판단할 때 사용하는 모델이다. 반드시 $\sigma_t^2$의 형식은 아니지만 루트의 형식이든 다른 형식이든 변수 자체가 포함되어 있으면 ARCH-M 모델이라고 합니다.